

Q: Why EC50 occurs at the recovery phase?
A: EC50 is not something that occurs at a point in time. EC50 is the concentration of drug that elicits 50% of the maximal response. Anytime the concentration reaches the EC50 value, the response will be 50% of the maximum. Thus, one can observe the EC50 as the response moves from 0 to 100% or when declining from 100% to 0%. In this model, there is a delay between observed concentrations and observed effects. Thus while effect is rising, the observed concentrations at that time will over-estimate the EC50. But after the system reaches equilibirium, the concentrations in plasma and effect site are proportional to each other. Thus during the declining phase, the observed concentration is more likely to be proportional to the EC50. That is why we used the declining phase of the response curve to generate an initial estimate for EC50.
Q: How did the built-in turnover model compare to the other models?
A: Very good question: We did not do a comparison during the demo. Here is what you find out after you append all Overall worksheets from the 3 different Phoenix model objects:
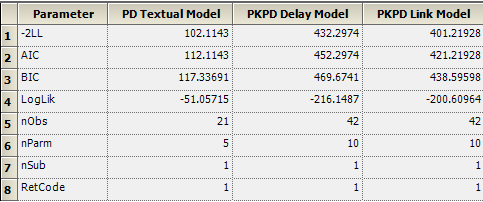
The best model (i.e. the model with the smallest objective function value, which is -2LL) appears to be the PD Textual model. This is because it requires a smaller number of parameters, so it is more likely to get a better fit. The difference in -2LL between the Link model (the actual built-in model) and the one with the delay statement is smaller, but it turns out that the fit with the Link model was superior to the one with the delay statement.
Q: Why did you need to run the built in?
A: We have presented three different ways of how to build up and run a model for the given data set. The idea was to give you more options to choose from when you want to build a model on your own
Q: Can the model compare option be used instead of appending the worksheets?
A: The Phoenix Model Comparer only works on population models. Although we had the population box checked under the Structural tab of the Phoenix model, we chose the Naïve-Pooled engine, that does not take into account intersubject variabilities, e.g. random effects. So the models we have shown in the demo were not true population models and hence could not be compared using Phoenix Model Comparer.









