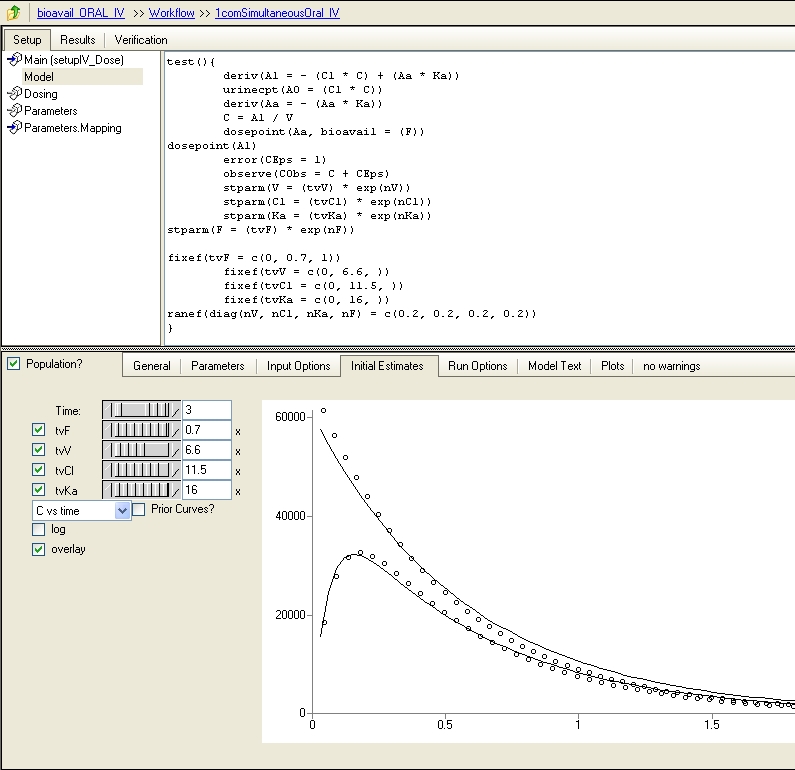
I'm trying to perform a simultaneous fit of oral and IV data on either classic WNL or Phoenix. I realize there is no canned model for this. Is my only option to write the code or edit graphically, and if so does anyone have suggestions on how I would do either of those? I also think there is some of the "old" ASCII text for this approach in the back of Gabrielsson and Weiner's book, but I cannot get my hands on a copy. Also, would the data input file (attached) be appropriate for this model? Thank you -Marc [file name=PK_question.xlsx size=20835]/extranet/media/kunena/attachments/legacy/files/PK_question.xlsx[/file]
Edited by Simon Davis, 03 May 2017 - 10:34 AM.