Hi supporter
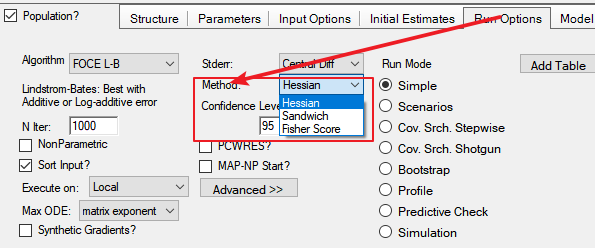
After activating the "NLME" license, there is an option for "Stderr Method." under the "Run Mode" tab of the Phoenix Model object.
This is the method of computing the standard errors.
I have some questions about the options:
1. The "Hessian" option is described in great detail in the help, which uses R-1 to calculate standard errors.
2. The "Sandwich" option may calculate standard errors using the R-1SR-1 approach.
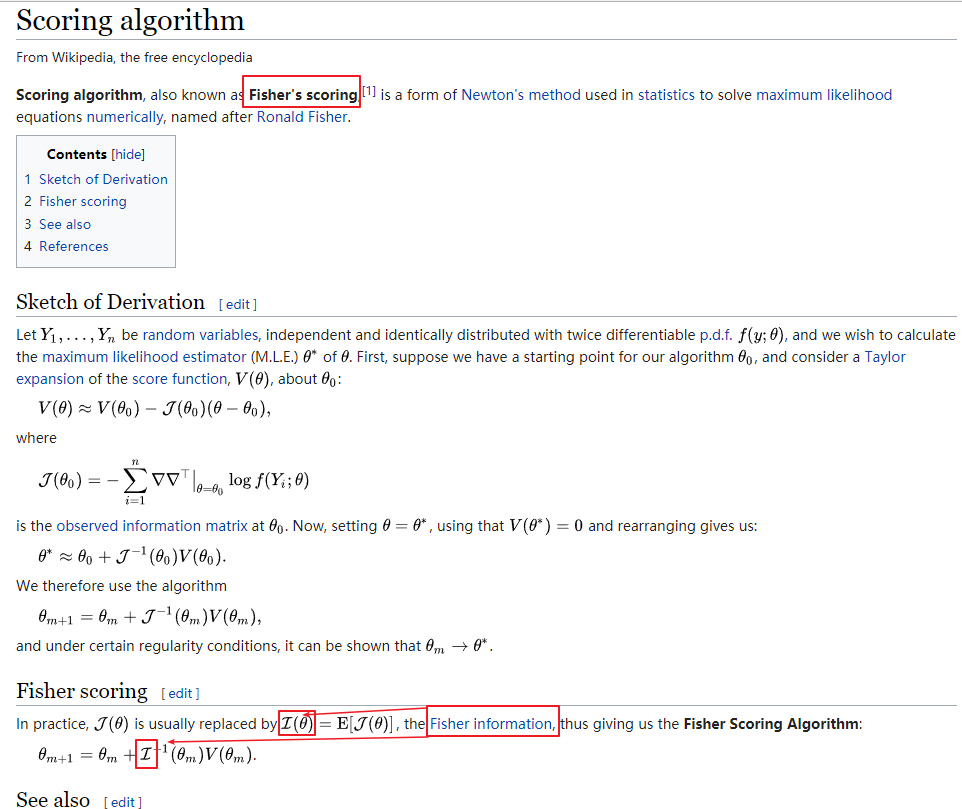
3. What does the "Fisher Score" option mean?
3.1 Use the 4S-1 method to calculate standard errors?
3.2 Use the inverse of Fisher's information matrix to calculate standard errors?
Cheers,
0521