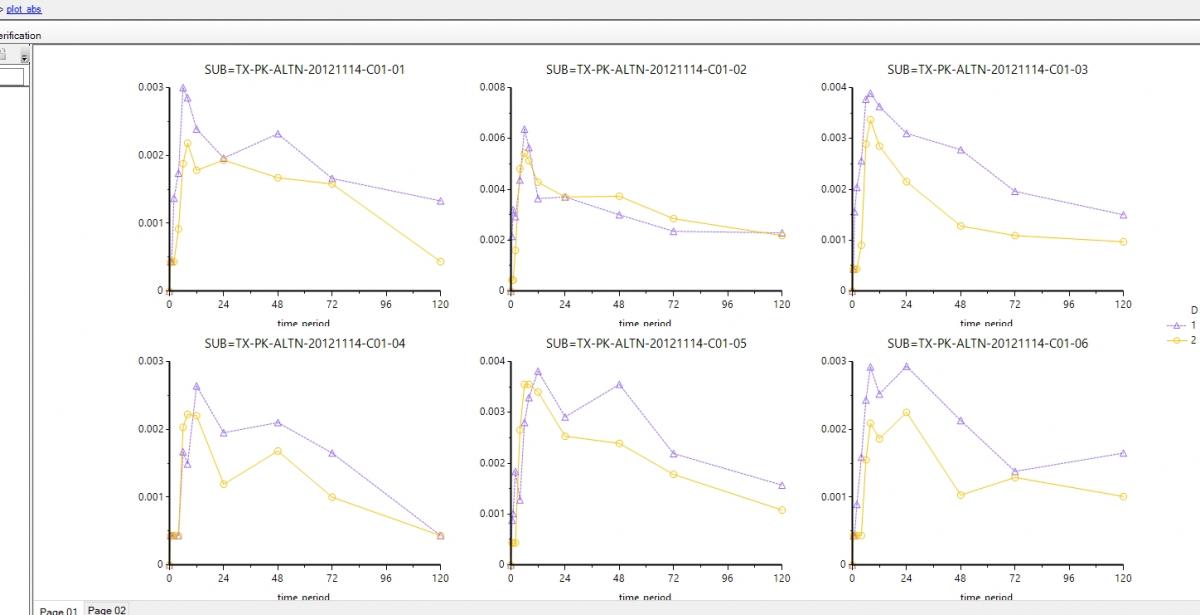
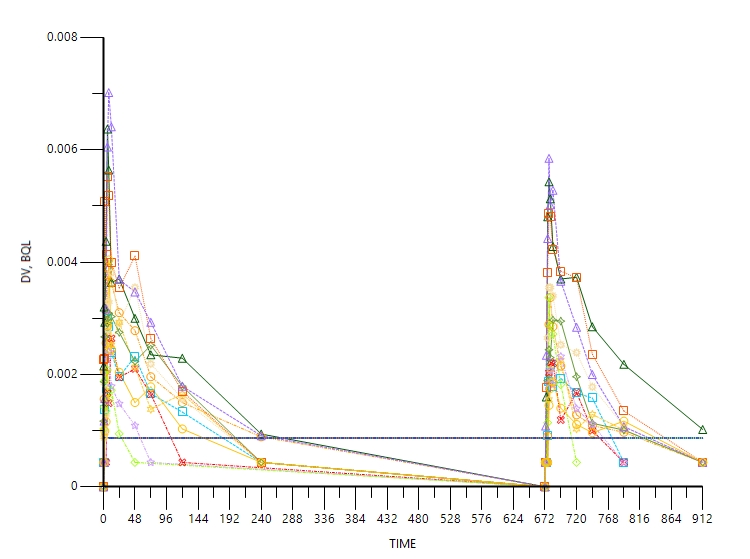
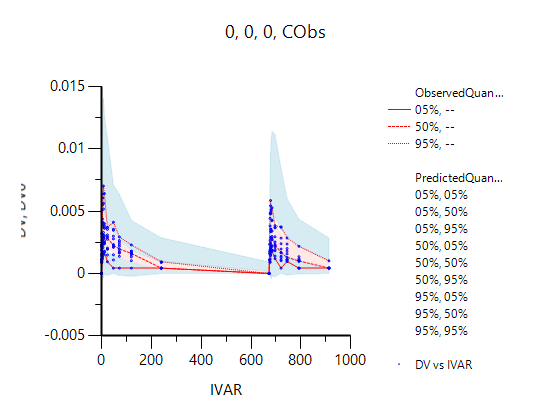
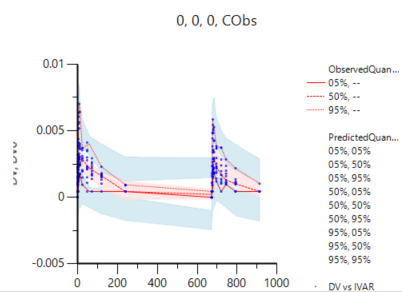
Hello all, I use additive\ multiplicative\add&mul error models to evaluate my base model. All error models can fit OK, but when I check the VPC results, the 5%/95% bounds under/overestimate the observed data for additive and add&mul error models.
So my question is whether my VPC setting for these two error models is right.
Can I do something to improve it.
What can lead to the negative values in this study (but not other studies)?
The file only shows one study, and I fit the same model to the whole studies. Actually the VPC problem only happened for this one. And overall the add&mul error model can reduce AIC significantly (~100 compared with multiplicative error model, and even better than additive) overall and give reasonable VPC to all studies except this one, which makes it a dilema, how can I select the final error model, as mentioning a bad VPC for one study is not a strong reason to select multiplicative over the mixed error model. This study represents 20% of the data points, 10% of the subjects, and the only food effect study.
Thanks
Attached Thumbnails
Attached Files
-
 0201133.phxproj 1.84MB
143 downloads
0201133.phxproj 1.84MB
143 downloads