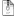Hi all,
I have a question regarding the control stream files generated by Pirana's Wizard tool.
I have attached screenshots of part of a Wizard control stream and an example control stream format provided by Icon PLC (creators of NONMEM), and am confused about their differences in implementing the residual error model in the ERROR block.
In the NONMEM example, the proportional and additive error model is applied to F to produce Y. This process is applied to both PRED and IPRED estimates. Also, the error parameters are stored in the SIGMA block.
However, in the Wizard control stream, IPRED is specified as F, meaning that the IPRED reported does not contain residual error as it should do, from my understanding. Then, a different form of error model is applied to F to attain Y (Y = F + W), and since sqrt(a^2 + b^2) is not equal to a + b, this does not equate to the usual formula for combined additive and proportional error. Finally, the error parameters are stored in the THETA block, meaning that NONMEM will treat them as fixed effects rather than random ones (for example, their shrinkage will not be calculated).
Is my understanding of the control stream correct? I would be grateful for any clarification anyone could provide, since I have seen the Wizard’s method of implementation throughout Pirana’s tutorials / documentation.
Many thanks,
Isaac
Attached Files
-
 Wizard Control Stream .png 464.09KB
0 downloads
Wizard Control Stream .png 464.09KB
0 downloads
-
NONMEM Control Stream.png 313.92KB
0 downloads