Hi,
the subject lines tells it already. Or did I miss something?

Advanced Member

Posted 07 August 2012 - 04:25 PM

Advanced Member

Posted 07 August 2012 - 05:17 PM

Advanced Member
Posted 07 August 2012 - 06:19 PM
Hello,
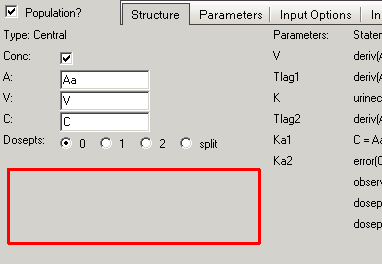
In graphical mode when select the green observation box you tick the BQL box
or
In textual mode :
observe(CObs = C + CEps, bql)
In both cases you will automatically get to map a CObsBQL in Main
Samer
Advanced Member
Posted 07 August 2012 - 06:59 PM
Hi Samer,
THX – this was it! Case closed. ;-)
Advanced Member
Posted 23 March 2013 - 01:42 PM
Does this treat the BQLs as per the Beal M3 approach?
if so are there any limitations you are aware of (i.e. patterns in the data where this approach might provide unreliable estimates, e.g. when the number of BLQs are >x% of the data; when the distribution of BQLs are concentrated in on part of the curve)?
Thanks,
Elliot
Advanced Member
Posted 24 March 2013 - 02:52 PM
Elliot,
The way PML handles BQL is identical to NONMEM's M3 method.
If the error model is log-additive, or if the error model is additive on log-transformed data, then it is identical to the M4 method.
Many PK data sets are fit better with the log-additive error model, or with log-transformed data. The overall effect BQL has is to penalize parameters for predicting too high.
Simon.
Advanced Member
Posted 24 March 2013 - 04:10 PM
Thanks,
So if I understand correctly (and correct me if that's an incorrect assumption):
-add a column in the input dataset
-create a flag for data which is to be censored
-the DV=0 if not to be censored
-the DV= 1 (or some other numberic non-zero values) if the value is to be censored
-select the BQL radio box if censoring is to be performed onthe BQL value
Where does the actual LLOQ go? or is it unecessary to specify this value the objective is to estimate this value regardless of what the LLOQ is?
Advanced Member
Posted 25 March 2013 - 10:49 AM
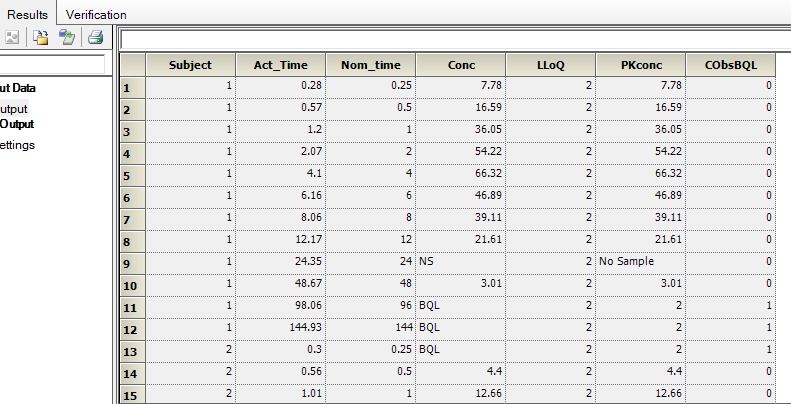
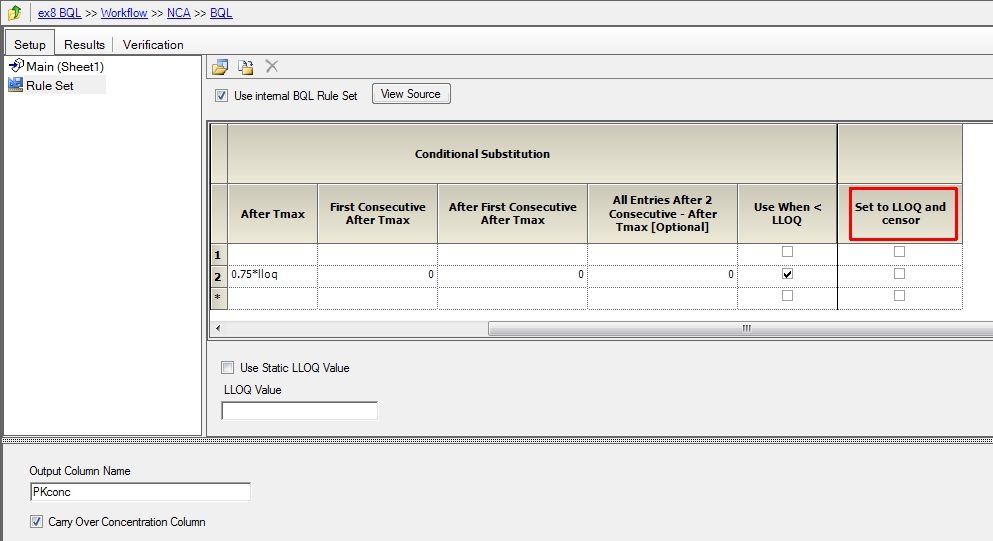
Elliot, Actually we provide a tool under the Data called BQL that will create the flag column CObsBQL for you. (leave the conditional substitutions all blank if you choose this option  you can use either a static value for LLoQ, or if it is already present in the dataset you can map it in (perhaps different assays used) then it will set the the column CObsBQL to 1 and the new column for concentration created to the value of the LLOQ when if finds the BQL value in the original conc column/or flag column. for non BQL observations the original conc will be passed through; take a look at the modelling sub workflow in the attached project. Simon. [file name=ex8_BQL.phxproj size=265885]http://www.pharsight.com/extranet/media/kunena/attachments/legacy/files/ex8_BQL.phxproj[/file]
you can use either a static value for LLoQ, or if it is already present in the dataset you can map it in (perhaps different assays used) then it will set the the column CObsBQL to 1 and the new column for concentration created to the value of the LLOQ when if finds the BQL value in the original conc column/or flag column. for non BQL observations the original conc will be passed through; take a look at the modelling sub workflow in the attached project. Simon. [file name=ex8_BQL.phxproj size=265885]http://www.pharsight.com/extranet/media/kunena/attachments/legacy/files/ex8_BQL.phxproj[/file] 
 ex8_BQL.phxproj 259.65KB
57 downloads
ex8_BQL.phxproj 259.65KB
57 downloads
Edited by Simon Davis, 10 July 2024 - 10:46 AM.
Member
Posted 22 October 2013 - 10:13 AM
Hi, firstly - thanks for this useful thread, as I was just trying to work out how to apply the Beal M3 rule in my Phoenix population model.
My question - does it matter what value you put in the observation data column for these BLQ values? I see that in Simon's example he has the LLOQ value (2) but I have a colleague who used LLOQ/2 - I think I'm right in thinking that the M3 model doesn't care what value you put, but I just wanted to check!
Kathryn
Advanced Member
Posted 22 October 2013 - 11:33 AM
Advanced Member
Posted 15 December 2013 - 06:28 AM
Dear Georgia
When you click on bql option in the residual error part of the model, you need to map CObsBQl with the censor column you have ion your data.
The censor column has the value 1 when an observation is BQL.
In the CObs column (your response column), you put the LOQ value when an observation is BQL. Therefore, you have 1 in the censor column and the LOQ value in the response column.
This applies to NLME.
Best
Serge
Advanced Member
Posted 15 December 2013 - 07:38 PM
Georgia, to add to Serge's comment; most labs supply values below LoQ (Level of Quantification) in a censored format e.g. < 10 so the value you would use is 10 with the CObsBQl flag of 1 as Serge indicated.
If you have actual values below LoQ from your lab then I believe you could use them with this flag too.
Simon








0 members, 0 guests, 0 anonymous users

