Hi Edouard,
I guess Phoenix is giving you an answer to the wrong question. In descriptive statistics generally we estimate the location (the arithmetic, geometric, harmonic means, the median, …) and dispersion (variance, SD, quartiles, percentiles, …) of a sample. No software is “clever” enough to know where
your data come from. Therefore, it gives you a lot of information by default (some more options have to be chosen if required) and it is up to you to select the correct ones.
Before applying any (!) statistics you have to think about the data generating process. Then –
and only then – you can select the most appropriate parameter(s) describing your data. Note: Any parameter implies knowing the data generating process and the underlying distribution. Example: If you report the arithmetic mean ± SD you essentially tell us
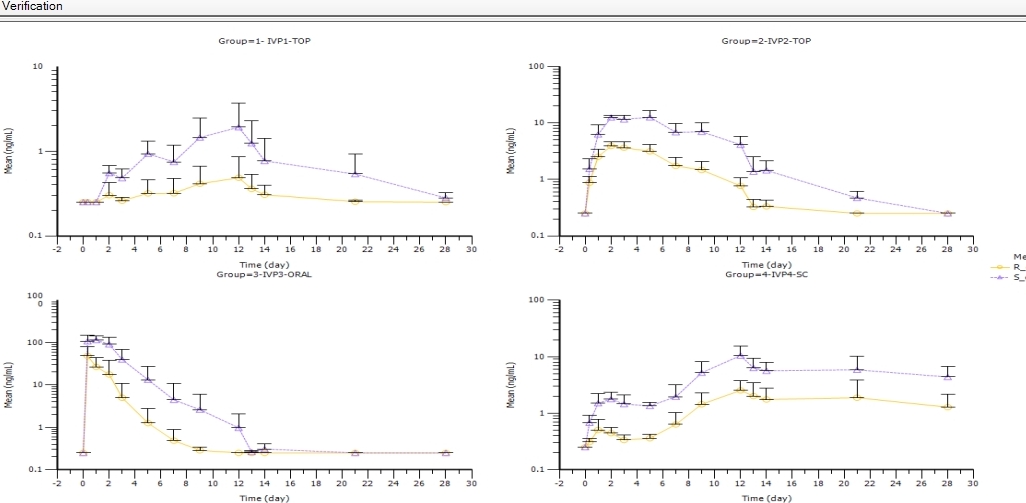
“the data were sampled from a normal distribution”. The normal distribution has a domain of definition from [–∞, +∞]. Does this make any sense for concentrations? Obviously not. Like many biologic variables they follow a
lognormal distribution, where the domain is ]0, +∞]. In PK I would recommend to simply throw the arithmetic mean into the garbage bin and report statistical parameters relevant for the lognormal, namely the
geometric mean and its SD (or CV).
In the setup in PHX tick ”Number of SD”. Send to XY Plot, map GeometricMean to Y, GEOLower1SD to Lower Error Bar and GEOUpper1SD to Upper Error Bar. Select a log Y-scale. Graphs > Error Bars > Content > User Calculation Type: Absolute
Now you’ll get a log-plot with
symmetric error-bars. If you want, switch to the linear Y-scale. The error bars will be
asymmetric now; exactly what we would expect from a lognormal distribution. BTW, they will
never be negative. Try it: Ask PHX for 10SDs. ;-)
Example:

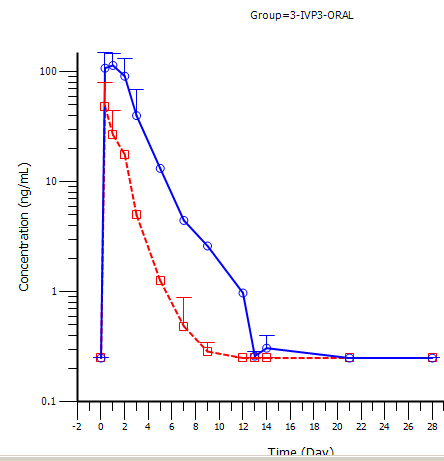
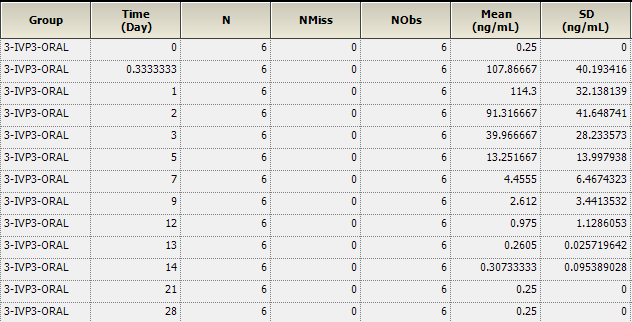
Below a recent bad example from the FDA (obviously produced by M$-Excel):

That’s plain nonsense. Do these “experts” (ha!) really expect (and this is what the arithmetic mean –SD suggests) that there is a ~6% chance to have a concentration of
– (minus!) 300 ng/mL?
If somebody insists on arithmetic means of concentrations, ask them:
Why? …and post the answer here, please. I’m always eager to learn something new.




 create a new project and import it
create a new project and import it