

Question: Why is the Freeze PK? box checked?
Answer: The Freeze PK option is checked when you want to fit PK and PD data in a sequential manner. This means that the PK and PD data are fit separately. First the PK data is fit to a model. Then the final PK parameters are used to simulate concentration values that are used to fit the PK/PD model. Here you would create two models: In a first step a model for the PK data alone. Once that is done you copy the model object and paste it back to the workflow. Next you will change the model type from PK to PK/Emax. Then you check the Freeze PK box to fix all PK parameters for the next run. Before starting to model the PK/PD data you would need to go to the Parameters Tab and look under Fixed Effects. At the bottom of this tab there is a button: “Accept All Fixed and Random”. When you click this button all initial estimates from the PK run will be replaced by the final estimates and will be used for the next run. Now you can continue building your PK/PD model: adjust the mappings and provide initial estimates for the PD parameters and finally run the model.
More generally, freezing any parameter(s) for which you already have good estimates is a usefulo ption, particularly when the degrees of freedom (Nobs – Nparm) is small. Using this approach reduces the number of parameters which must be fitted.
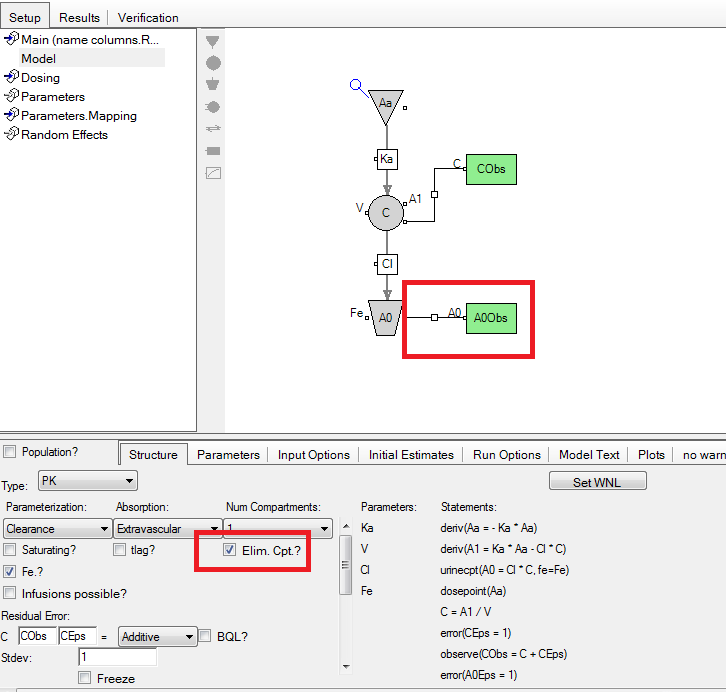
Question: What is Elim-cpt and when is it used?
Answer: An “Elim-cpt” is a collection compartment. The most common example is urine, where excreted drug is collected until the bladder is emptied. Another example could be feces or exhaled CO2. The check box Elim-Cpt in the Structure Tab gives you the option to fit urine data. Once activated you will see a new observation block in the graphical model ( see picture attached) and another column ‘A0Obs’ will appear in the main mapping panel. Here you would map your measured amount excreted.
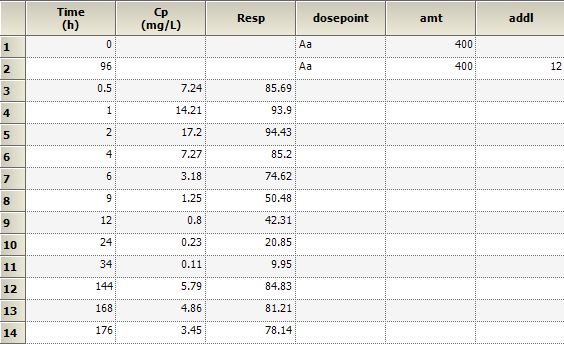
Question: Do we need to use ADDL option for additional doses or can we enter dose time and dose for each additional dose in the input file?
Answer: Using ADDL is not required; you may specify the dose amounts and times in the input file or as an internal worksheet under Setup | Dosing. However, the ADDL option under Input Options Tab allows users to add identical doses in a highly efficient way, particularly if there are a large number of profiles being analyzed and/or large number of doses being administered. With ADDL, you provide the dosing interval, the dosepoint and the dose amount. The input sheet needs to contain a column with name ‘ADDL’ that provides the number of identical doses that should be applied.
Question: How to set Initial Estimates of tvKa 1? tvV, tvV2 tvCL tvCL2? V and CL from NCA? how about V2 and CL2?
Answer: On one of the slides we showed where to look for initial estimates in NCA:
· Cl = from NCA (CL_F_obs)
· V2= from NCA (Vz_F_obs)
For V1 we divide the Dose by the Cmax value as reported by NCA
For Cl2 we typically take the value from Cl as initial estimate.
For Ka we typically start with 1.
And for tlag we just take the timepoint of the first measurable concentration after dose
There might be some confusion about structural parameters like V (Volume) and fixed effects like tvV (which means typical value of Volume). In our webinar series we are adopting the language from population modeling where the structural parameter is typically defined as a combination of a fixed effect (which is typical for a population) and a random effect that accounts for between-subject variability (BSV). As we are only doing individual modeling and not population modeling we don’t have random effects therefore the distinction between structural parameters and fixed effects is not necessary. However, we want the community to become familiar with the population language and therefore making the additional effort and writing the code with both structural parameters and fixed effects.
Question: Can you share the final phoenix project file together with the slides on your server?
Answer: All materials which include the slide deck, the textual model and the link to the recorded webinar are made available through our forum at:
https://support.cert.../34-pml-school/
We are not allowed to share the Phoenix project files. These are files that are distributed with the book: Gabrielsson & Weiner, Pharmacokinetic and Pharmacodynamic Data Analysis - Concepts and Applications, 5th Edition, Swedish Pharmacology Press (2015)
Question: How usual is it that you do not need to model an effect compartment?
Answer: Whenever there is a delay between the time course of the concentration and the effect we would suggest to include an effect compartment to your PK/PD model. The effect compartment is a theoretical concept that models the delay in effect, it accounts for the distribution of the drug from systemic blood to the biophase or site of action. Since for most drugs the site of action is distant to the venous compartment, I would guess that a delay in effect is a common situation. Whether this needs to be modeled by an effect compartment is another discussion.
Question: Can you have 1 input worksheet with both: DOSING, PK and PD datas?
Answer: Yes, this is a very compact format. For the data set in our exercise we need to merge the PK data with the PD data using Time as a sort key. Then you can add 2 dosing records to the top making use of the ADDL option (described above) for specifying the doses.
Question: If I have urine volume and concentration data during multiple period of time, is it useful to add the urine data into the PK model? How?
Answer: If you have plasma and urine data available we would encourage you to do a simultaneous fit of all the data.There are two exercises on this topic in Gabrielsson and Weiner’s book: PK5/6 – One compartment intravenous plasma/urine I&II, that will serve as a very good entry point.
If you want to setup a plasma/urine model in Phoenix on your own, you need to check the box Elim. Cpt? In the Structure Tab under Num Compartments. This allows you to map excreted amounts in the main panel.
Question: What is the advantage of closed form over open form?
Answer: The closed form uses a mathematical solution for the movement of drug between the compartments. The open form uses differential equations solved during the minimization process. The closed form model runs faster because it requires less CPU cycles to calculate a mathematical solution compared to differential equations. Both methods will give the same results.
Question: Unchecking the closed form means we are doing Michaelis Menten Kinetics?
Answer: Sorry about the confusion, we were talking first about the Saturation check box and then about the Closed Form check box which happens to be located just below each other. It is the “Saturating” check box that switches the model to a saturable elimination that is defined with the Michaelis Menten equation, e.g. Vm and Kmax will be estimated for the concentration at half of maximal metabolic rate and Vmax as the maximum metabolic rate. Unchecking the Closed Form check box means that differential equations will be used instead of algebraic forms.
Question: Plots with a lot of data points versus only those with those at the time of observed data - is that not a built in function/plot? if not, will it be?
Answer: By default, the plot outputs in the Phoenix model object only produce predicted concentrations at the times when there are observed concentrations. This is the reason why the default plot of observed and predicted vs IVAR may appear “jagged” – the small number of default predicted points.
A way to ask the Phoenix model to produce more predicted concentrations was shown in the webinar. On the Run Options tab, add a table, and then use the Sequence statement to define which predicted time points to include in the table. For example, if time is in hours, seq(0,100,1) would produce a predicted concentration every 1 hour from 0 to 100 hours.
From here you can make an overlay plot as was shown in the webinar. We have filed an enhancement request to add more predicted points to the default Phoenix model plot output.
Question: How can we get the raw data for the PK analysis? I have the Gabrielsson book.
Answer: Depending on the edition of the book that you have at hand, the data sets were typically distributed on floppy disks or CDs that came with the book. You can take off the data sets from there.
Question: How do we get secondary parameters?
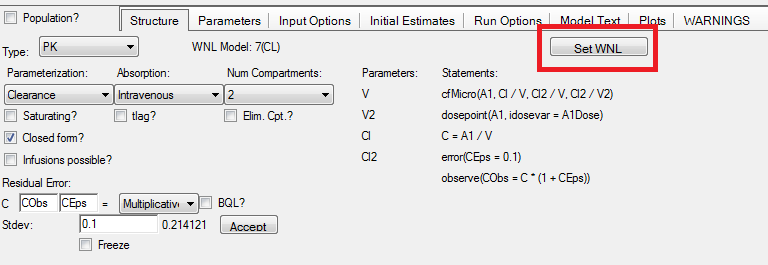
Answer You can define secondary parameters on the Parameters Tab of the Phoenix model, there is a Secondary Subtab where you can add your own definitions:

Typical definitions of secondary parameters you can find under the classic WinNonlin libraries that you can access through the Set WNL button:
Question: How to validate those parameters via bootstrapping?
Answer: Bootstrapping is only available in population mode and we are doing individual modeling. With one subject we only have a single set of PK/PD parameters. Bootstrapping involves re-sampling the dataset by randomly selecting subjects from the original dataset to create a new dataset for analysis. Then this “new” dataset is analyzed and final parameters are obtained. This is repeated multiple times (200-2000 or more) to get a distribution of final parameter estimates. As you can see it is only possible to run this type of bootstrap if you have multiple subjects that are being fit to a population model.











