Hi Simon!
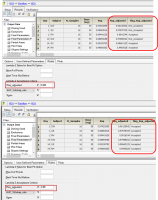
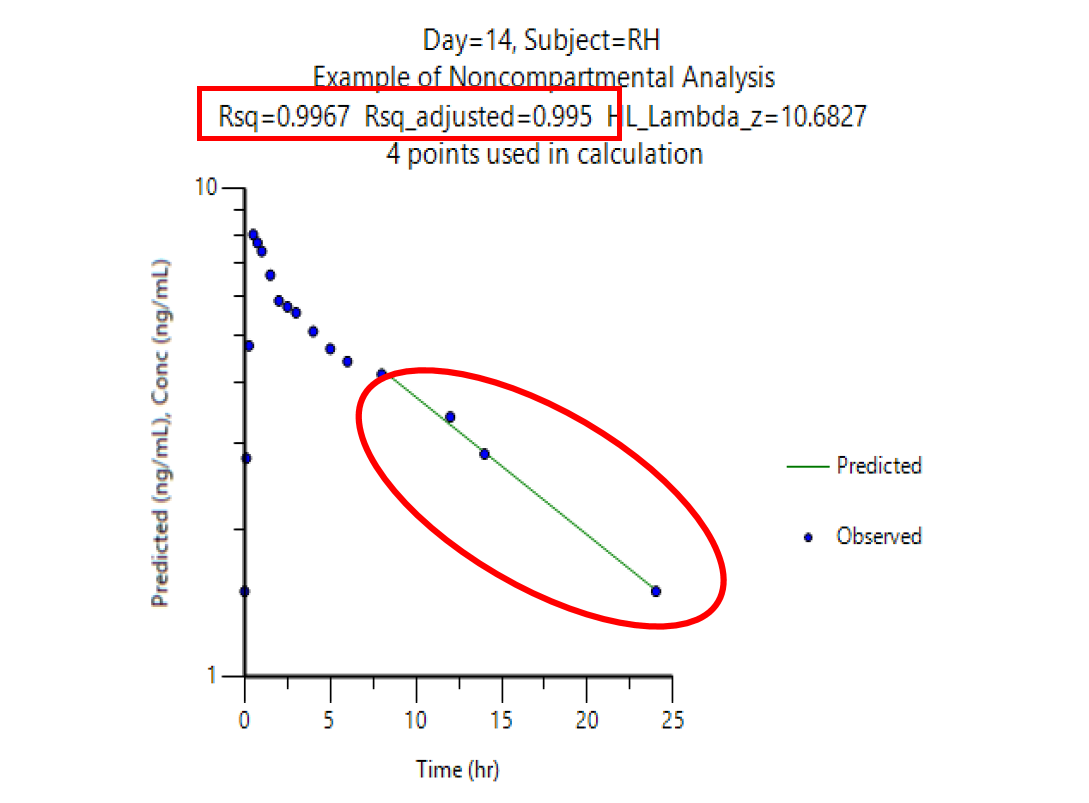
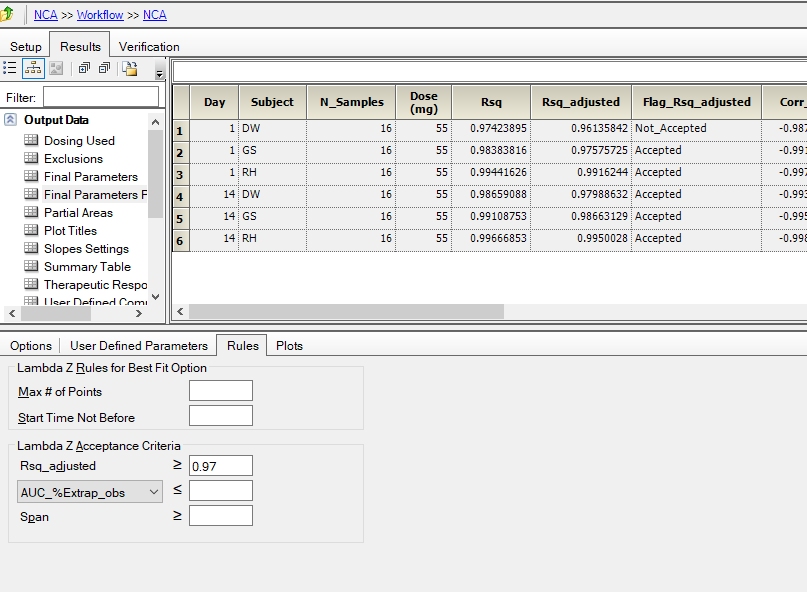
I’ll try to watch it. BTW, sneaked around the corner (PKanalix). Like in PHX/WNL the bloody linear trapezoidal is the default (did you see this one?). When it comes to estimation of λz, the trainers pointed out that inspection of the fits is important.
IMHO, I disagree with some of your points.
1. The most critical assumption about the cornerstone of your full text:
Apart from the few drugs which are subjected to capacity limited elimination like C2H5OH,
any pharmacokinetic model can be simplified to a sum of exponentials
This is very, very obviously wrong!(any→some, or any pharmacokinetic model of chemical drugs on the market )
As we all know, all pharmacokinetic processes are nonlinear, and the linearity we observe is just an accident and coincidence. When the reaction occurs in the range of 20-80% of the Emax model, we can think of it as a kind of approximate linearity. That's why almost all of our drugs do Dose Escalation Trial to look for so-called linear ranges (forgive my ignorance, I can't find a quote).
2. So after that, all your conclusions are based on the assumption that "the observed blood concentration data are all within the linear range of the drug."
It is within the linear range,→ so it is obvious that the elimination is the first-order rate, and further, the elimination is the first-order rate,→ then it is better to naturally use the logarithmic trapezoid method.
3. As we all know, the study of pharmacokinetics is a gradual process. At first we knew nothing about the kinetic process of the drug, and in the end, we could even accurately predict the drug-time curve of an individual who had not collected any blood concentration. That is, generally speaking, the study of pharmacokinetics can be divided into:
Scenario 1, exploratory research (very little prior information, or none at all),
Scenario 2, research to improve accuracy (there is a lot of prior information, but we need more data to improve the accuracy of our model).
For scenario 1: when you don't know the result, whether it's linear trapezoidal or logarithmic trapezoidal, you're throwing dice because you can't evaluate accuracy.
For scenario 2: obviously, linear elimination use logarithmic trapezoid, nonlinear elimination use linear trapezoid! which is also very clear, there is no logarithmic trapezoid is always the best.
So, the one that should be thrown into the dustbin is "I have a correct model".
Essentially, all models are wrong, but some are useful.
— George E Box. In: Box GEP, Draper NR. Empirical Model-Building and Response Surfaces. New York: Wiley; 1987. p. 424.
Of course, if you are mainly exposed to chemical drugs BE trials, then congratulations! you are mainly engaged in "precision improvement research", and it just so happens that they are almost all linear elimination, which allows you to repeatedly prove your own great conclusion that "all drugs are linear elimination" in practice, and then make you feel confident in your own experience.
Sincerely,
0521
Edited by 0521, 17 June 2022 - 04:32 PM.